







本篇文章目录导航:
【题目】探讨Docker技术的Hadoop性能优化方法??
【第一章】Docker技术的Hadoop性能优化研究绪论
【第二章】Docker技术的相关知识背景介绍
【3.1-3.2】系统环境搭建和内存配置分析
【3.3-3.5】基于Docker容器的Hadoop架构平台搭建
【第五章】YARN性能优化研究
【第六章】异构系统下数据安全问题
【第七章】Docker技术中Hadoop性能的优化结论与参考文献
第三章系统环境搭建和内存配置分析
为了分析Hadoop性能,本文搭建了基于Docker容器的Hadoop测试平台。本章首先介绍搭建系统所需的软件环境和硬件环境,然后具体讲述如何在Docker容器中搭建Hadoop分布式平台。接着通过对比实验分析出恰当的内存配参数,为后文异构环境下数据安全的研究打下基础。
3.1系统环境搭建
3.1.1硬件环境
本实验是通过实验室SuSE集群虚拟化平台进行搭建。
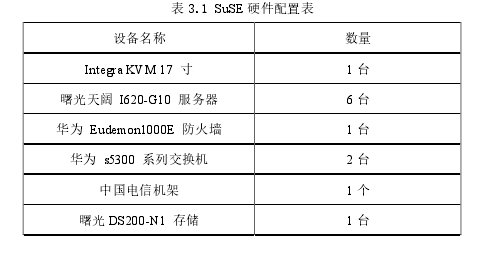
SuSE集群虚拟化平台架构图如图3.1所示,硬件配置如表3.1所示。
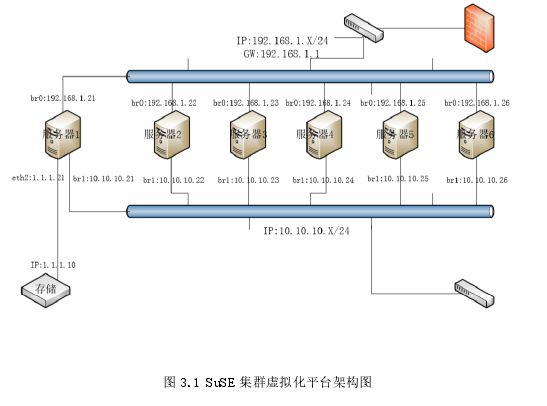
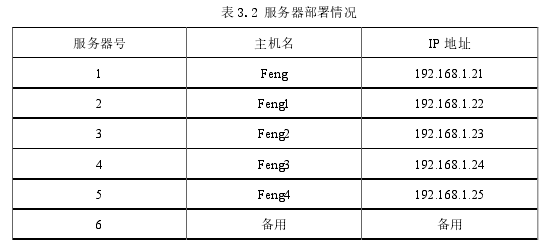
服务器的具体配置参数如表3.2所示:
防火墙配置情况:默认管理员feng;password:
admin/Admin@123;可以通过管理端口;管理站点IP是192.168.0.1出口IP是10.10.21.123,接口是GE0/0/0.
本次实验从曙光天阔I620-G10服务器中选择了其中的5台,剩余的一台服务器作为备用。
5台服务器其中一台作为Master节点,主机名为feng,另外4台作为Slave节点,名称分别为feng1、feng2、feng3、feng4.
3.1.2软件环境
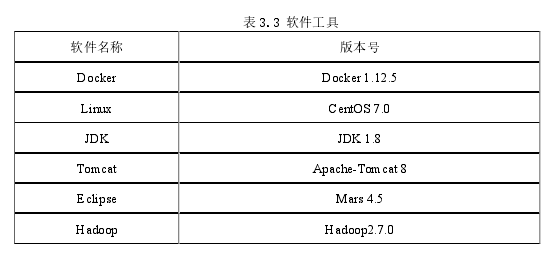
整个基于Docker容器技术的Hadoop平台架构搭建过程中所需要的软件开发工具如下表3.3所示:
3.2系统方案的实现
3.2.1Docker容器集群的搭建
首先,在实验室5台服务器上面,通过使用Dockerpull命令在DockerHub中完成Docker的下载、解压和安装。为了方便管理每个服务器上的Docker容器集群并且使容器集群的调度更加高效,还有为了更便捷的Docker容器之间的跨服务器的通信,本文的方案采用了Kubernetes----Google公司研发的大规模容器集群管理工具。把各个子服务器上的Docker容器部署到主服务器上的kubectl中。实现代码如下:

3.2.2Hadoop平台的搭建过程
Hadoop分布式集群是由1个主节点和4个从节点组成,通过Docker的openvswitch完成节点之间的部署。并且Kubernetes集群架构在主服务器中Docker容器中更加高效的完成了容器之间的管理、自动更新、调度等功能。
通过Docker容器构建Hadoop平台架构的过程总体可以分为四步骤:(1)通过Dockerfile下载、解压和安装Hadoop的基础镜像。(2)配置SSH→JDK的安装及配置环境变量。(3)配置Hadoop分布式相关文件。(4)Hadoop镜像构建。
安全外壳协议SSH(SecureShell),它主要是在应用层层面(经扩展后,传输层也可以)上的一款安全性的协议。像ftp、telnet等传输协议存在些安全隐患,比如在明文传输未加密协议时候,很有可能被从“中间截断”.SSH可以解决这一个问题,SSH有良好的压缩加密功能,在数据的传输方面,具有良好的保密性与快速性。所以,SSH大量应用于网络传输中。
本实验采用SSH无密码登录,因为Hadoop部署在Docker容器中,所以要保证无密码访问容器和保证无密码访问Hadoop.最后还要对ApacheTomcat的进行配置并且对hadoop-env.sh、core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml等配置文件完成部署工作。
(1)core-site.xml是配置HDFS(Hadoop分布式文件系统)的关键所在,此时,需要对其端口号和地址进行匹配。


(2)hadoop-env.sh可以进行hadoop的环境变量的配置。

(3)yarn-site.xml配置作用是保证Hadoop性能的重要因素,同时也可以提供权限给浏览器查看集群部署的权限。

(4)hdfs-site.xml的配置是负责修改HDFS的备份方法。

(5)mapred-site.xml配置的作用是给与Map/Reduce并行化、分布式算法重要的权限。

3.2.3Docker集群部署方案
因为Hadoop平台是一个规模很大的分布式集群平台,所以在处理大规模数据的时候,Docker必须启动很多的容器来获取容器的镜像。为了更简洁更有效率地管理和调用Docker容器集群,本方案需要用到一个大规模的容器集群管理架构--Kubernetes.
Kubernetes的内部架构源自Borg,这是GoogleGroup内部的一个大型集群管理工具。
Kubernetes不仅继承了Borg功能系统,还在主机之间部署,管理和应用容器。
因此,Kubernetes的设计理念是为开发人员和用户提供简单方便的容器集群操作。通过这种方式,它建立了一个负载平衡框架机制,该机制集成了容器的自动存储,备份,调度和重启。
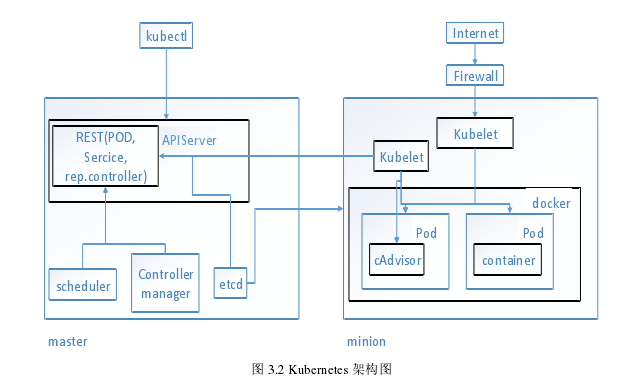
Kubernetes的工作原理如图3.2所示。左侧和右侧块代表Kubernetes的两个重要节点:负载管理用户和资源管理节点-主节点;minion节点负责容器操作监控。
主节点主要由两个组件组成,Rest和APIServer.
Rest负责资源调度和用户管理。具体来说,它是资源对象的接口。调度程序通过一系列调度算法调用Rest接口来控制和管理容器。
Kubernetes控制器管理器依赖于在主节点上运行的集群更新和控制服务节点。
APIServer负责响应来自minion节点的用户的请求。在KubernetesAPIService中,必须在响应请求之后将任何节点的添加,删除,检查和修改的消息发送到后台存储etcd.
Minion节点可以分为两个主要组件:
kubelet和pod.集群中所有docker容器的维护由kubelet组件完成。在kubelet中,kubeletServer进程负责存储所有docker容器的所有信息,然后反馈给Pod中的ContainerAdvisor.
Pod不仅是minion节点的重要组成部分,也是整个Kubernetes的灵魂。
Pod就像一个容器,所有容器都被打包到Pod容器中,就像货物一样。
当用户执行大规模容器调度时,Pod就像一个容器,以及内部的货物(容器),从一个主机服务器(主机)到另一个主机服务器。因此,它是Kubernetes容器集群部署管理的最小单元。
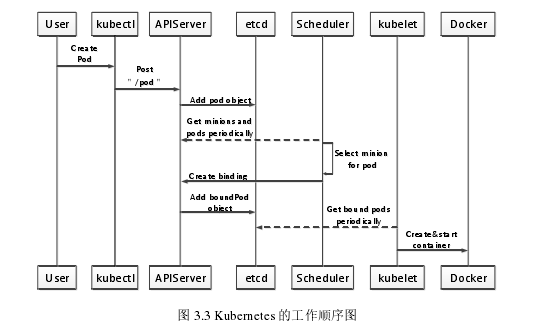
如图3.3所示,这是Kubernetes核心组件工作的序列图。当用户向Kubernetes发送容器集群请求管理时,首先创建Pod,然后在接收到请求时,kubectl向APIServer中的“/pod”节点发出post请求请求以提供源容器配置文件。在API验证kubectl的成功请求后,它将执行一系列基本源文件配置任务,并添加或创建用于调度后台工具(etcd)的pod接口。然后,在调度程序将创建的pod接口绑定到etcd的后台管理体系结构之后,它可以执行kubelet的资源管理,调度,操作和同步更新。
kubelet存储Docker容器的向量,因此当调度kubelet时,kubelet会向DockerAPI发送容器创建或打开请求。最多的Docker容器集群还实现了资源管理和调度。可以看出,这个Docker容器的资源调度过程可以看作是“ectd的资源调度过程”.
综上所述,为了解决大型Docker容器集群部署,调度,更新和管理效率,稳健性等问题,本文提出了构建Docker集群的完整解决方案,即Kubernetes管理Docker容器,在Docker容器中部署并提取和创建Hadoop镜像。这形成了一套基于Docker容器技术的完整Hadoop平台。