







本篇文章目录导航:
【题目】探讨Docker技术的Hadoop性能优化方法??
【第一章】Docker技术的Hadoop性能优化研究绪论
【第二章】Docker技术的相关知识背景介绍
【3.1-3.2】系统环境搭建和内存配置分析
【3.3-3.5】基于Docker容器的Hadoop架构平台搭建
【第五章】YARN性能优化研究
【第六章】异构系统下数据安全问题
【第七章】Docker技术中Hadoop性能的优化结论与参考文献
3.3 基于 Docker容器的Hadoop架构平台搭建
3.3.1Docker中搭建
Hadoop平台Docker最初是dot Cloud公司内部的一个项目,研发于2013年初,是一个开源的项目。
它基于Google公司推出的Go语言实现。
Redhat已经在其RHEL6.5中集中支持Docker;Google也在其Paa S产品中广泛应用,实现轻量级的操作系统虚拟化解决方案这Docker项目的刚开始的目标[51].
Docker的基础是Linux容器(LXC)等技术。为了让用户不需要去发时间注意容器的管理并且使得操作更为简便,Docker在LXC的基础上进行了进一步的封装。
这样用户就可以简单地像操作一个快速轻量级的虚拟机一样操作Docker的容器。
在操作系统中基于虚拟化的容器将会共享系统中的么一个应用程序,这个方法既为每个应用程序制定了标准化,同时又允许在任何的Linux环境中运行应用程序。例如实验的系统为Linux环境,在实现文件系统存储时Linux系统采用两层结构。
Docker容器的特点之一便捷性,使Docker能在多台机器中运行,并且可以瞬间启动程序和更加有效地利用存储器。
Hadoop目前被广泛用于大数据分析。
Docker是一种新的容器技术,它是Apache Hadoop的新Quick Start选项。在云或集群中的Docker环境中构建Hadoop集群是一种趋势。
但是,如何更好地利用硬件资源并提高Docker环境中的Hadoop性能对用户来说是一个挑战。
在本章节中,本文研究了Docker环境中Hadoop的内存配置,并在改变Hadoop的内存配置的同时分析了Hadoop的性能。本文选择两个不同的应用程序(CPU密集型应用程序-Word Count和内存密集型应用程序-Tera Sort),并根据CPU和内存占用情况来测量其资源使用情况。本文使用的Docker 1.8.2版本,hadoop 2.7.0版本,并采用Dockerfile方法来部署Hadoop.
Dockerfile方法构建Hadoop镜像的时候,可以更方便的进行接口、端口等环境的配置工作。主要完成如下几步工作:
(1) 下载基础系统镜像。由于需要在分布式中部署 Hadoop,Docker在创建时候需要将密钥文件通过SSH服务配置成为参数文件存储进Docker容器中。
(2) 使用 Dockerfile的内建指令下载安装软件。主要安装2个配置文件首先是Java JDK的安装,然后是Hadoop的下载和解压。
(3) 使用 Dockerfile内建的指令加载对应的配置文件。首先,利用Dockerfile把配置文件发送至Docker容器里;接着,配置SSH环境,让容器可以在开启Docker的同时自动开启Hadoop;最后,对外暴露网络端口号。
(4) 最终,完成在 Docker完成Hadoop镜像的构建:执行docker build-tsequenceiq/Hadoop-docker:2.7.0指令。
3.3.2 内存优化的原因
Apache Hadoop是Map Reduce最着名的实现之一,广泛用于集群和云环境。
Docker技术可以轻松创建,部署,控制和管理容器,因此基于容器的云计算正在成为一种趋势。通过将一个软件封装在一个完整的文件系统中,Docker容器包含软件运行所需的所有内容。
Map / Reduce是一种可用于数据处理的编程模型。
Map / Reduce基本上是并行运行的,因此它为在分布式平台上并行处理数据提供了大量有效的解决方案。其优点是并行处理大规模数据集。因此,Map / Reduce可以生成大规模数据,并且可以分析任务通过足够的计算机分发到任何数据中心。
Docker技术的优势会使容器容易被创建,部署,控制和管理,因此,云计算在Docker中的应用越来越广泛。一个Docker容器包含所有软件运行的必备条件,例如代码,运行时间,系统工具和系统库,这保证软件将总是以相同的方式运行,而不管容器的外部运行环境。
要实现Hadoop的最佳性能,对于应用程序开发人员和系统用户来说是一个挑战。研究人员已经表明,Hadoop配置在Map Reduce程序的性能中起着重要的作用。适当的参数配置可以减少作业的执行时间,并有效利用集群资源来提高作业的吞吐量。但是,在调整Hadoop集群时存在许多挑战:
(1)Hadoop的性能可能受到堆栈的每个组件(Hadoop、JVM、OS、网络基础架构、底层硬件以及可能的BIOS设置)的影响。
Hadoop有大量的配置参数,这些配置参数对Hadoop的性能有一定的影响。
(2)配置依赖于应用程序,即优化的配置是特定于应用程序的特征和输入数据集。
CPU密集型应用,内存密集型应用,I / O密集型应用和网络密集型应用在优化配置方面存在差异;(3)Docker带来了创建Hadoop集群的灵活性。
通过更改Hadoop的内存配置,物理机可以运行不同数量的Hadoop节点。这为优化配置中的Hadoop集群带来了复杂性。由于Hadoop和Docker的普及,本文研究了Docker环境中的Hadoop配置。内存资源是运行Map Reduce作业的一种关键资源。本文通过改变Hadoop的内存配置来研究内存设置对Map Reduce作业和资源利用率的影响。对于CPU、I/O、网络和Docker容器的设置,本文仅使用默认配置。
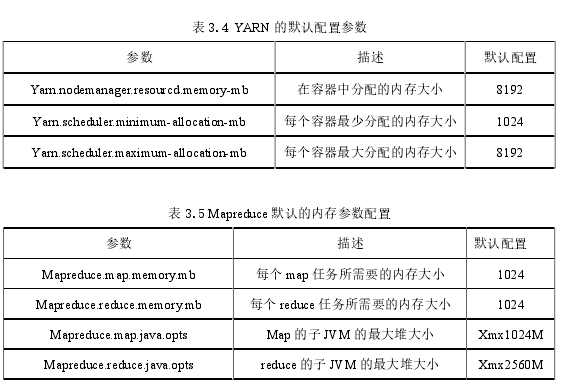
3.3.3Hadoop的默认内存配置参数
Hadoop技术作为云计算技术的开源实现,对云计算技术的发展起到了十分重要的作用。
现在大多数的企业和科学研究采用了Hadoop作为云计算平台。
Hadoop凭借它简单的并行编程模型,庞大的数据存储能力和高效的计算能力为用户提供了良好的客户体验。在Hadoop集群中,适当平衡内存、CPU和磁盘的使用是非常重要的,以便处理不受任何一个集群资源的限制。
Hadoop提供了一组默认的配置文件,内存相关参数及其默认值如表3.4和表3.5所示。
3.4 实验测试与结果分析
3.4.1 实验方案
本实验的方案是通过改变Hadoop在Docker容器中的配置参数来分析它与默认配置参数的性能对比,来验证内存配置参数对其性能的影响。
实验选择两个典型的评测基准来评估Hadoop的性能:
(1)Word Count基准,代表了一个典型的用例,是一个CPU密集型的Hadoop标准基准。
(2)Tera Sort基准,代表了另一个典型的用例,主要是内存密集型的Hadoop标准基准。
在Word Count实验中,部分RFC文件(1112个文件和53MB)的文件名匹配“rfc1 * .txt”,被选为输入数据集。
Tera Sort实验中的输入数据集大小为10GB,由Tera Gen应用程序生成。
在实验中,为操作系统,YARN和HDFS保留了6GB的RAM,所有的集群节点都将有90GB RAM.在实验中考虑了五个内存参数,其设置在表3.6,表3.7,表3.8,表3.9中示出。
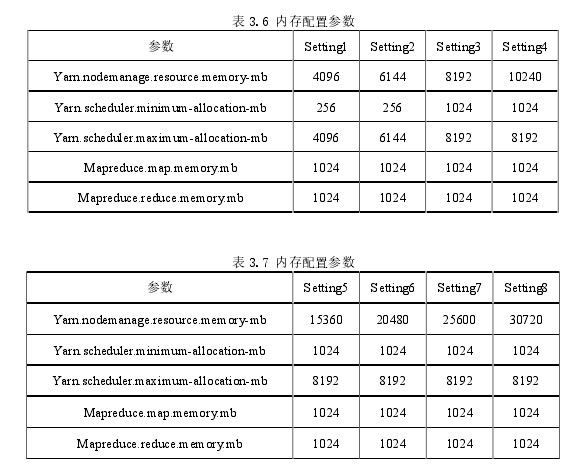
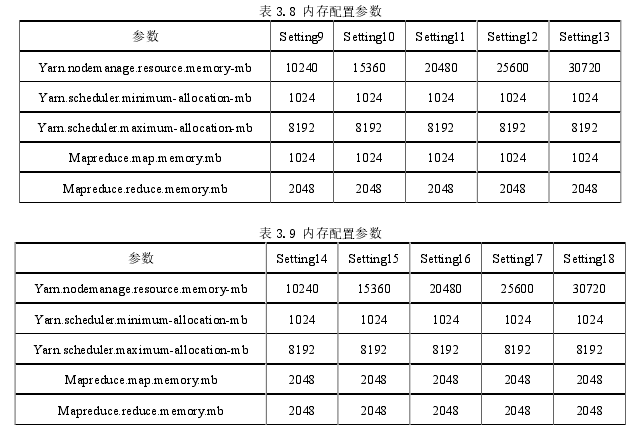
在表3.6中,mapreduce.map.memory.mb和mapreduce.reduce.memory.mb已被设置为2048MB,而yarn.nodemanager.resource.memory-mb的值从10GB到30GB不等。在实验中,集群的大小设置为3,实验结果是5次运行结果的平均值。
3.4.2yarn.nodemanager.resource.memory-mb对Word Count的影响
参数yarn.nodemanager.resource.memory-mb表示可以为任务容器分配的物理内存量。在实验中,该机器有96GB RAM.假设参数yarn. nodemanager.resource.memory-mb是NM(MB)RAM,集群的大小是DN,剩余存储量是:
RM(MB)RAM:
RM = 96GB-NM×DN其中RM(MB)RAM用于操作系统、JVM、YARN和HDFS.Word Count实验结果如图3.4所示,mapreduce.map.memory.mb和mapreduce.reduce.memory.mb的值设置为1024MB.图3.4显示当参数yarn.nodemanager.resource.memory-mb的值设置为4096MB时,Hadoop的性能较低,并且当yarn.nodemanager.resource.memory-mb的值从8G到30G改变时,性能下降非常缓慢。
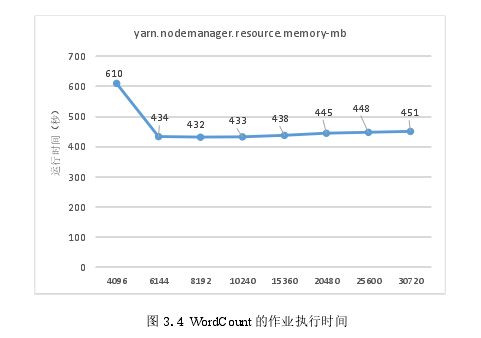
当执行Word Count时候,CPU资源是一道瓶颈。
Word Count运行的平均CPU占用率如图3.5所示通过分析图3.5的CPU使用情况,发现当yarn.nodemanager.resource.memory-mb的值被设置为4096MB,则CPU占用率为大约53%.而在其他实验情况下,CPU占用率平均超过96.7%.当yarn.nodemanager.resource.memory-mb的值被设置为4096MB时,由于内存资源短缺,Hadoop无法为作业创建足够的map和reduce任务,因此其性能比较低。在其他实验案例中,由于CPU资源短缺内存增加,Hadoop无法增加map和reduce任务,因此性能不能提升。
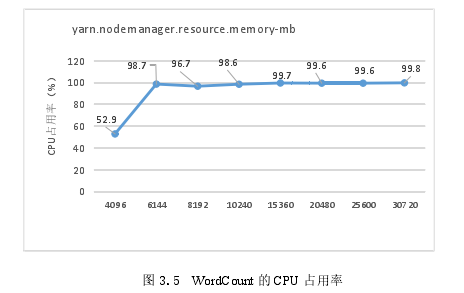
3.4.3yarn.nodemanager.resource.memory-mb对Tera Sort的影响
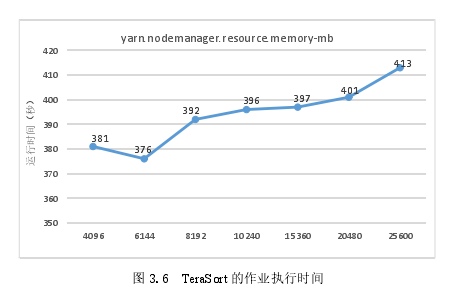
Tera Sort是内存密集型的,因此在Tera Sort实验中为HDFS保留的内存应该大于在WordCount实验中保留的内存。在实验中,yarn.nodemanager .resource.memory-mb的值从4GB到25GB不等。实验结果如图3.6所示,其中mapreduce.map.memory.mb和mapreduce.reduce.memory.mb的值设置为1024MB.
除了内存,CPU资源对Tera Sort也很重要。在map任务完成之前,Tera Sort是CPU密集型和内存密集型,但之后它只是内存密集型。因此,Tera Sort作业执行周期分为两部分,同时分析CPU和内存使用情况。
Map任务完成之前的周期称为map-phase,Map任务完成后的周期称为reduce-phase.
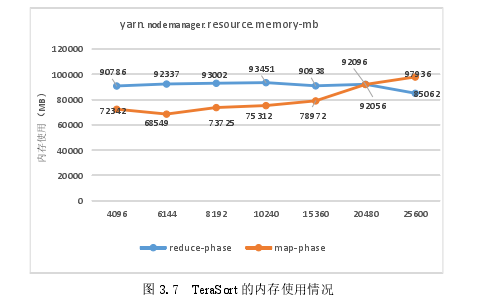
Tera Sort的平均内存占用率如图3.7所示。
Tera Sort的CPU的平均占用率如图3.8所示,在Map阶段和Reduce阶段的Tera Sort的运行的线程数如图3.9所示。通过分析图3.8和图3.9,发现Map阶段中CPU使用率较高,随着yarn.nodemanager.resource.memory-mb的值从6144MB变化到25600MB,在Map阶段运行的线程数随之增加。
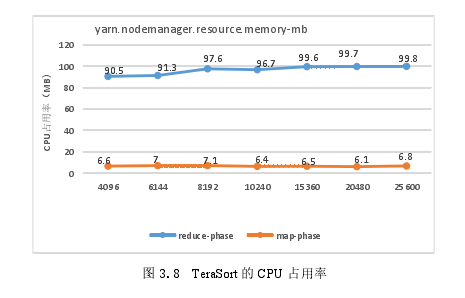
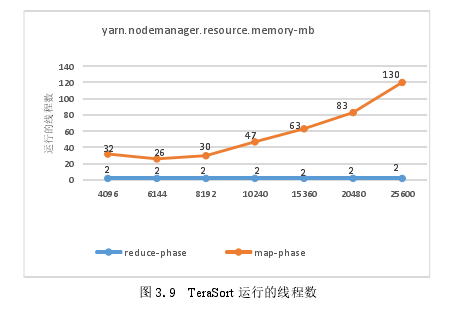
当yarn.nodemanager.resource.memory-mb值被设置为4096 MB时,内存资源不够无法创建足够的map和reduce任务,所以性能不能达到最佳点。随着内存资源的增加,更多的Map和Reduce任务已被创建,并在CPU上运行更多的线程。随着线程数量的增加,线程的切换造成开销的提高,导致Hadoop性能的下降。
3.4.4 实验结果
在本节中,已经在Docker环境中测试了不同的Hadoop内存配置,并且讨论和分析了内存参数和Docker容器数量对Hadoop性能的影响。
实验结果表明,当内存是节点的瓶颈时,通过增加分配给节点的内存可以提高Hadoop的性能。
但是,当内存不是瓶颈时,增加分配给节点的内存可能会导致性能下降。通过分析内存和CPU使用情况,发现随着内存资源的增加,将创建更多的map和reduce任务,并在CPU上运行更多的线程。
实验结果表明,参数yarn.nodemanager.resource.memory-mb对占用CPU资源的应用程序的性能影响不是很大,但内存密集型应用程序的对它的性能有很大的影响。测试结果还显示,当yarn.nodemanager.resource.memory-mb的值大于10GB时,mapreduce.map.memory.mb和mapreduce.reduce的值较大性能越好。
3.5 本章小结
首先本章介绍和分析当前社会流行的Docker容器技术和Hadoop平台。根据实验室现有的硬件资源,通过Docker容器技术对环境和文件进行配置、镜像进程处理。
Docker容器负责Hadoop的节点参数配置,Hadoop平台则作为Docker的镜像运行,并且在Docker容器中部署Hadoop分布式平台架构。接着设计实验方案,通过改变Hadoop的默认内存参数配置来对比分析其性能。本章研究了Docker环境中Hadoop的内存配置,并在改变Hadoop的内存配置的同时分析了Hadoop的性能,并根据CPU和内存占用情况来测量其资源使用情况。本文已经做了大量的测试,测试结果表明,与默认的Hadoop配置参数相比,适当的更改配置参数可以提高Hadoop性能。