







本篇文章目录导航:
【题目】探讨Docker技术的Hadoop性能优化方法??
【第一章】Docker技术的Hadoop性能优化研究绪论
【第二章】Docker技术的相关知识背景介绍
【3.1-3.2】系统环境搭建和内存配置分析
【3.3-3.5】基于Docker容器的Hadoop架构平台搭建
【第五章】YARN性能优化研究
【第六章】异构系统下数据安全问题
【第七章】Docker技术中Hadoop性能的优化结论与参考文献
第四章 YARN性能优化
在基于内存参数配置优化的Hadoop平台基础上,YARN集群管理对Hadoop的性能也有很大的影响,所以要优化YARN设置最佳并发级别来获得最佳的性能。本章首先介绍YARN优化问题的由来,并且分析了Mapreduce并行化工作,并行执行的效率由Map和Reduce配置的容器数量和资源化分控制。接着通过实验,在有限的计算资源内,设置并发级别使执行效率最大化,从而优化Hadoop的性能。
4.1YARN的优化
4.1.1YARN问题
由来近年来,计算机行业的数据量以指数级的增长,对计算机的计算能力和存储容量提出了更高的要求,并且分布式存储和计算技术得到了迅速发展。
Hadoop的平台使用最广泛。其中Yarn是Hadoop2.0之后的调度机制。设计调度算法时不考虑节点的性能差异。然而,由于采集时间,硬件和软件配置,在实际情况中,计算设备通常具有计算节点之间的性能差异,这可能导致节点之间效率不是最佳。
Hadoop是一个分布式存储和并行计算框架。由于其高可靠性,高可扩展性和高容错性,Hadoop广泛应用于云计算。资源分配和调度问题一直是并行计算领域的一个重要问题。
Hadoop资源管理系统YARN提供了三种内置资源调度程序,但随着应用程序的扩展,这些内置调度程序无法满足用户的需求。因此,如何合理分配和调度资源,提高系统资源利用率,缩短系统计算时间,从而提高系统性能,降低成本,具有重要意义。
HadoopYARN是分布式的计算框架常用于处理海量的数据。分布式应用程序能否有效利用计算资源取决于计算的数量以及应用程序数据被分割的块(Block)。给定一组计算资源和计算任务,为工作划分恰当的数据块,以便在有限的计算资源内更有效地提高性能。
HadoopYARN结合Hadoop分布式文件系统(HDFS)可以被认为是一个分布式操作系统的功能,类似于专有的TandemNonstop内核。现在可以使用了YARN作为分布式的通用框架计算。在分布式计算框架,全局调度程序分配任务的节点和本地调度器之间的工作量管理提交给节点的任务。
HadoopYARN将系统资源分区到容器中并启动它们的任务。并发容器的数量取决于分配给它们的资源的多少。如果资源被粗略分割,那么可并行运行的容器数量将会受到限制。如果资源被细分,大量的容器可以并行运行。当一个Hadoop作业部署在云平台上,这是必需为平台选择足够的资源以保证执行时间,保证在最少的资源内获得最高性能,本文需要配置YARN框架设置最佳并发级别,是Hadoop性能最佳。
4.1.2Mapreduce并行化工作
本文需要一种机制将一份工作分成两份相同大小的工作,用来评估性能对并发级别的依赖性。出于这个目的,本文已经使用了Map Reduce提供简单的方法去控制间隔大小通过控制map任务的数量。
Map Reduce在2004年由谷歌引入,Map Reduce是一个软件框架使用分而治之算法进行并行处理,分发处理非常大的数据文件在一个大的机器集群上。使用并行算法可以有效的解决这一问题。
由Google提出的Map Reduce并行计算模型主要是针对海量数据的处理,相对传统的并行计算模型,它由底层对数据分割、任务分配、并行处理、容错等细节问题进行封装,极大的简化了并行程序设计。在使用Map Reduce进行并行计算开发时,用户只需集中注意力在自身要解决的并行计算任务上。高性能是通过分解处理来实现的小部分工作可以在集群中并行运行数百个节点。
Hadoop分布式文件系统(HDFS)是一个整体Hadoop的组件,用于存储和复制大型文件跨群集的多个节点。
在Map Reduce计算模型中,作业由一个集合组成自动并行化任务称为Map和Reduce任务。这些任务的多个实例是分布式的分布在集群节点上创建的容器上。
Hadoop将输入数据分成较小的块和一个Map任务将被分配处理每个块的责任。并行执行的程度由Map和Reduce配置的容器数量任务控制。在单个节点上运行的容器数量可以对它们的性能、CPU和内存利用率有显着的影响。实现计算资源的最大利用率并保证作业完成时间,选择适当的并发Map/Reduce任务数量是至关重要的。太少的Map/Reduce任务数量增加了工作完成时间没有有效利用资源。
启动大量的Map和Reduce任务会导致I / O争用,抢占磁盘I / O资源。因此,必须选择适当并发Map和Reduce任务数量使得资源是最大限度地利用,从而让性能最佳。
4.2 实验环境
实验环境由4个Hadoop集群组成,其中3个节点被配置为工作节点/数据的节点HDFS的节点。英特尔Hi Bench基准测试工作负载工具用于评估不同级别并发性的性能。每个节点将有16个逻辑核心。因此总数3个工作节点上的可用资源将是48GB内存。可用的总存储空间分布式文件系统大约是1.5TB.
每个节点都运行在Cent OS7.0版上。该集群使用Hadoop版本2.7.0进行配置。一个节点是主节点专用于资源管理器和HDFS的Namenode.
英特尔Hi BenchBench标记工具,在不同的并发级别上的工作性能是使用IntelHi BenchSuite6提供的一个工作台标记工作负载来确定的。这个工具允许本文使用Random Text Writer创建所需大小的输入数据文件,并运行标准应用程序来处理数据。使用Hi Bench工作负载的Micro-bench类别中可用的Wordcount工作负载评估工作绩效。
Wordcount是CPU绑定作业与中等磁盘I/O计算输入文本文件中每个单词的出现次数。
它是测试正常Map Reduce作业的split,reduce和map操作的基本Map Reduce操作之一。输入文本文件存储在HDFS上,块大小为256MB.
输出文件也在HDFS上创建。
HadoopYARN架构分布式调度是关于将大量任务分配给整个集群中相对较少数量的可用工作节点的决策过程。
Hadoop2.0中引入的YARN负责集群资源管理和调度。
Hadoop YARN集群允许本文运行需要使用并行处理来提高性能的各种应用程序。
YARN上的Map Reduce应用程序只是一个选择。
YARN是一个动态调度程序,它使用静态配置信息来实时做出决策。
YARN通过将任务分配给负载较轻的节点来实现负载分担,一旦任务分配给节点,就不会通过将运行任务重定位到集群的其他节点来进行动态负载平衡。
YARN是一个集中的动态调度程序,其中调度的责任物理地驻留在主节点的单个节点上。它可以被认为是一种协作式调度算法,其中节点管理器(NM)和应用主控(AM)之类的分布式实体相互配合以进行调度决定。
YARN资源管理器(RM)以容器为单位分配系统资源。容器是可定制的资源集合,如CPU和内存。当作业被YARN接受时,它在其中一个节点上创建容器0,并在其上启动AM.
每个应用程序必须有一个AM,它们在容器0(也称为AM容器)中运行。
AM负责按照工作要求启动后续的Docker容器。容器是运行任务执行的基本可调度单位,它们是由AM根据要求由RM分配。应用程序任务同时或顺序地在一个或多个容器上运行,具体取决于可以同时运行的容器数量和任务总数。
节点管理器在群集的每个节点上运行,创建执行容器并根据来自RM的请求监视它们。
它与RM交换心跳,AM协调和管理工作;与RM协商安排任务,任务由节点管理器启动。
AM容器将在其中一个从节点上运行,并在作业完成后被销毁。
一个或多个容器可以部署在集群的一个节点上。节点上容器的数量取决于分配给容器的总资源的一小部分。当一个作业运行时,对于每个任务,容器被创建并在执行结束时被销毁。
在容器的创建和销毁方面存在固定的开销,并且任务执行时间必须远远高于这个开销,才能充分利用并行处理的好处。
用于实验研究的Hadoop集群由4个具有相同计算资源的节点组成。一个节点被指定为主节点,其余3个节点被用作工作节点。资源管理器在主节点上运行,作业块在工作节点上运行。
YARN调度程序使用容器来运行称为任务的作业块。容器由专门分配CPU和内存的计算资源分区组成。容器大小决定了可以运行集群中每个节点的最大并发任务数量。
4.3 容器大小和配置资源划分
容器资源分配的配置参数在每个节点上定义,提高了在群集的节点上部署具有不同容量的容器的选项。运行Map Reduce作业,需要具有相同的容器计算能力。这是为了确保属于作业的所有Map和Reduce任务同时完成。具有相同硬件的节点的集群上的容器资源分配相当容易,因为只需要考虑内存和CPU内核的分配。如果节点具有不同的硬件能力和CPU计算速度,那么定义具有相同处理能力的容器变得非常困难。
YARN配置允许本文将系统分区到分配有专用资源的容器中。目前所考虑的资源是内存和CPU.将CPU划分为资源的需求已经存在了很长一段时间。
HadoopYARN引入了一个名为“vcores”的新概念,即虚拟内核的缩写。应该设置多少的决定取决于群集中运行的工作负载类型以及可用硬件的类型。一般的建议是将其设置为CPU密集型任务的节点上的物理内核数量。
但是,对于通常在Hadoop环境中看到的I/O绑定任务,可将核心值设置为物理核心的4倍 . 这 有 助 于 实 现 更 高 级 别 的 并 行 性 并 提 高CPU利 用 率 . 通 过 引 入Dominant Resource Calculator,在Capacity Scheduler中实现了对CPU作为资源的支持。在集群每个节点上的xml文件hadoop-2.7.0/etc/Hadoop/yarn-site.xml用于指定YARN配置参数。表4.1给出了定义容器的内核和内存的配置参数。容器的资源分配是通过指定最小值来控制的并最大限度地分配内存和核心。
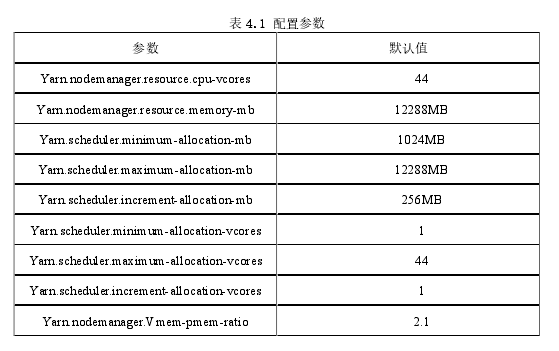
虚拟内存分配受节点管理器的限制。任务如果超过了允许的虚拟内存限制,则会被终止。
虚拟内存分配配置在多个物理内存中。默认情况下,它是容器的物理内存的2.1倍。例如,如果一个容器配置了1GB的物理内存,那么它将不能超过2.1GB的虚拟内存。这可以通过YARN配置文件中的yarn.nodemanager.vmem-pmem-ratio属性进行调整。
YARN可以配置为在一个心跳中允许多个容器分配以获得更好的性能。
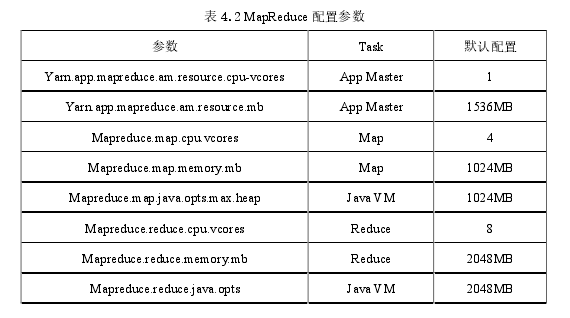
YARN在hadoop-2.7.0/etc/Hadoop/mapred-site.xml中提供了一个xml配置文件来为Map Reduce作业指定容器的资源分配。通过使用这个配置文件,本文可以专门为应用程序主控执行资源分配Map Reduce作业的任务。表4.2中显示了Map Reduce特定的配置参数。
应用程序主容器可以在群集的任何一个节点上启动。因此,本文需要为集群的所有节点上的应用程序主容器保留资源。在Hadoop分布式计算框架中,当运行Map Reduce作业时,作业的Map任务总数取决于输入文件的大小和块大小。对于每个文件块,将分配一个Map任务。
HadoopUber模式被禁用,以创建一个运行时环境,类似于在单独的JVM上启动容器的巨大工作负载。
在测试环境中,输入文件大小为9GB,块大小为256MB.
所以共有36个Map任务。
在Hadoop集群中,并发映射的数量取决于容器形式的资源分区。留下操作系统所需的内存和CPU资源,系统有12GB的内存和44个可以分配给HadoopYARN集群的核心。当分配给容器的资源较少时,可以运行更多并发Map数量和集群容量利用率也在增加。表4.3显示了Map任务的并发性,Map任务数量,波数和容器资源分配之间的关系。此表基于群集的3个工作节点上可用的总资源。
定义容器大小的Map Reduce配置以6种不同的方式完成,如表4.3所示。并发执行状态下的map任务的数量将由Map Reduce配置文件通过为属性mapreduce.map.cpu.vcores和mapreduce.map.memory.mb设置合适的值来控制。
reduce任务被配置为在全部完成之后运行,以便容器得到重用,map和reduce任务之间不会有任何资源争用。
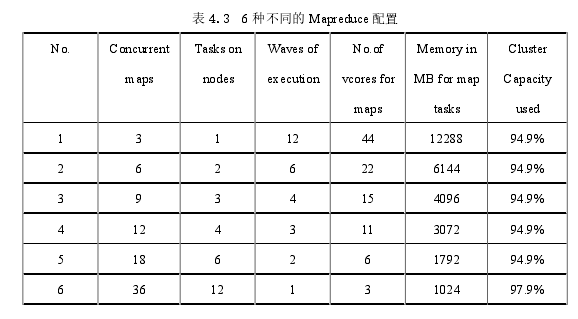
在HDFS上创建大小为9 GB的文本文件。
Hi Bench套件中的Word Count工作负载将在每个配置下运行。观察每种情况下作业的总执行时间,以及在表4.2最后一栏中显示的群集容量利用率。
Reduce任务的数量配置为8,并且与Map任务相比,它们的执行时间是很少的。
执行时间的主要作用于作业的Map阶段。
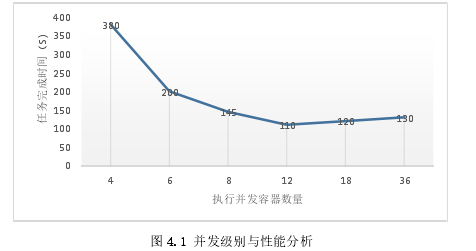
4.3.1 任务并发和工作完成时间
各种并发级别的工作完成时间如图4.1所示。在图4.1中看到节点级别的并发性,这表示每个节点上的一个Map任务,在这种情况下,并发级别为12任务完成时间最短。在36个并发的最高级别,将会有12个Map任务运行在每个节点上。
表示执行时间对并行性的依赖性的模型通过使用SPSS软件包的非线性回归分析来创建。
该模型由?? = ??(??)形式的非线性函数表示,其中??是执行时间,??是执行并行度。公式(4.1)给出了数据生成的模型。
?? = ?? + ?? ??????(?????) + ????2(4.1)在公式(4.1)中,?? = 110.0,?? = 720.0,?
? = 0.33,?
? = 0.02.
参数??取决于硬件平台,并决定基本性能水平。参数?
?,??和??独立于硬件平台。这些参数取决于YARN调度程序和执行中的任务粒度。可以看出,执行时间最初是指数衰减的并在基础性能水平上下定论。
执行时间随着并行性水平的提高,非线性地增加到超过基准水平。因此,在超过这个基本阈值水平的情况下,并行性没有任何优势。全局和本地调度器将性能影响到并行性的阈值水平。
本地调度程序中的开销和磁盘I/O拥塞负责超出并行性阈值级别的执行时间的增加。
性能的阈值级别取决于系统资源。在具有16个逻辑核心和16 GB内存的测试机器中,实验配置了4个逻辑核心和4 GB内存的容器。这使得节点级别的并发性为4.在具有单个硬盘的服务器上,建议使用集群中每个节点上可用的逻辑内核和可用物理内存的四分之一来定义容器。这确保了在群集的每个节点上将同时运行4个任务容器。
4.3.2 实验结论
如果定义少量的大容器,则会导致计算资源的利用率降低,并增加执行时间增加。如果定义了大量的小容器,将会更好地利用集群资源。但是,由于内存和I/O子系统的资源争用,执行时间可能不会减少。在运行Map Reduce作业时,重复使用容器来运行Map和Reduce任务是很常见的。因此,在所有Map任务完成之前,Reduce任务不能启动,并且延迟完成单个Map任务可能会延迟Reduce任务的启动。这项实验表明,在一个节点上可以运行的并发容器的理想数量取决于物理内核的数量和系统内存。建议在集群的每个节点上定义具有1/4可用逻辑内核和1/4可用物理内存的容器。这确保了在群集的每个节点上将同时运行4个任务容器。在这个实验结果中,12个并发集群容器为最佳并发级别,可以使效率最大化性能最好。
YARN在Hadoop中引入了一个灵活的资源管理器。此资源管理器可帮助为Hadoop批处理应用程序分配系统资源的专用部分,留下其余资源用于开发和运行通用应用程序。现在,可以在Hadoop集群上运行各种以Scala,Python和R等语言开发的应用程序,从而可以将其用作强大的分布式计算框架。分布式应用程序的性能取决于通过明智地选择作业的组件任务的并行级别来有效利用集群中可用的计算资源。单磁盘系统的性能取决于本地调度程序的开销和磁盘I/O拥塞。云服务器上的CPU和内存资源将根据集群节点上可支持的执行并行性约束来选择。
4.4 本章小结
本章分析了YARN,介绍YARN优化问题的由来,并且分析了Mapreduce并行化工作,执行的效率由Map和Reduce配置的容器数量和资源化分控制。接着通过实验,在有限的计算资源内,设置并发级别来获得执行效率最大化,从而优化Hadoop的性能。在一个节点上可以运行的并发容器的理想数量取决于物理内核的数量和系统内存。在本章实验的结果中,YARN集群管理设置并发级别为12,可以使Hadoop效率最大化性能最好。