







本篇文章目录导航:
【题目】研究深度学习的目标检测与搜索算法??
【第一章】基于深度学习的视频运动目标绪论
【第二章】学习视频运动目标相关工作
【第三章】基于卷积神经网络的视频目标定位检测
【第四章】基于时空双流的视频人物动作检测
【第五章】基于循环神经网络的视频目标自然语言搜索
【第六章】目标检测与搜索算法的结论与参考文献
第五章 基于循环神经网络的视频目标自然语言搜索
第三章已经阐述了如何使用基于边界概率的定位模型的来实现目标检测定位准确性的修正,并且将定位模型代替了原理目标检测流水线中边框回归算法,实现了在视频帧中更高的定位精确性的目标识别,第四章中分析了视频中人物的动作识别,所提出的基于时空双流的3D卷积神经网络,充分利用了视频帧的时间序列上的信息。接下来,本章将重点研究如何通过自然语言搜索出视频帧中的目标。
5.1 问题描述
自然语言对象搜索就是要有效的返回视频帧中搜索的目标。具体的说来于给定的一张视频帧或者图像和一句检索目标的自然语言描述,能够通过提取视频帧或者图像的特征以及自然描述语的特征,查询出视频帧或者图像中搜索目标的位置。
目前以及有了一些视频图像检索方面的研究。比如Wu等人[54]中提出了一种基于词袋(Bag of Words)模型的自然语言检测。对于给定的一些候选物体区域,使用基于Image Net的数据集卷积神经网络分类器,获得这些候选目标区域的类别名称,将这些类别名称都放入到一个单词集合当中,获得图片对应的词袋(Bag of Words),并且将这个词袋(Bag of Words)与自然语言搜索语句进行匹配。
Donahue等人提出了一种基于LSTM网络的图片文本描述的生成模型,模型名称为LRCN.该模型通过词组映射层(Word Embedding Layer)与2个LSTM层组成,可以将词组序列特征以及图片特征分布输入。然而,一个问题是自然语言标注数据集中数据量不多,很难获得训练较好的网络;还有一个问题是,现如今的自然语言搜索方法中,并没有对搜索目标的空间位置信息以及搜索目标在整个上下文环境的信息充分利用。
基于以上的问题,本章在Donahue等人提出的图片标注生成LRCN模型的基础上,提出的一种能够充分利用空间位置信息以及上下文环境的信息的模型SGRC(Spatial GlobalRecurrent Conv Net),并且能够通过迁移学习的方法在其他领域数据集上先进行预训练,解决了自然语言标注数据集数据不多的问题。
5.2 基于GRU自然语言搜索模型框架设计
本章提出的基于GRU的自然语言查询模型(SGRC)的框架图如图5.1所示,该模型主要包含如下部分:三个门循环单元GRU(Gated Recurrent Unit)分别记做GRUlocal、GRUglobal和GRUquest、两个卷积神经网络分别记做GRUlocal和GRUglobal、一个词嵌入层(Word EmbeddingLayer)和一个词预测(Word Prediction Layer)层。该模型设计首先获取候选目标、候选目标的空间位置信息、全局环境以及查询的语句的特征描述;接着通过GRU单元融合上述的特征,通过词组预测层来完成目标的搜索。




5.3 SGRC 模型的迁移学习
众所周知,现有的自然语言目标搜索数据集有着数据量过小的缺点,不能训练参数较好的网络。因此本章提出了迁移学习的方法来解决这个问题,通过在其他领域的数据集上进行预约训练得到初始的网络参数,之后再在自然语言目标搜索数据集上训练微调网络。本节将通过预训练网络以及微调网络参数两个方面对模型迁移学习进行阐述。
5.3.1 图片文本描述
数据集上的预训练本节主要讲述了本章提出的SGRC模型如何在其他领域数据集上的预训练。为了使SGRC模型的词嵌入层(Word Embedding Layer)、词预测层(Word Predicting Layer)和三个GRU循环单元获得良好的初始化参数,本章提出的SGRC模型将在图片-标注数据集上先进行学习,获得部分初始参数。
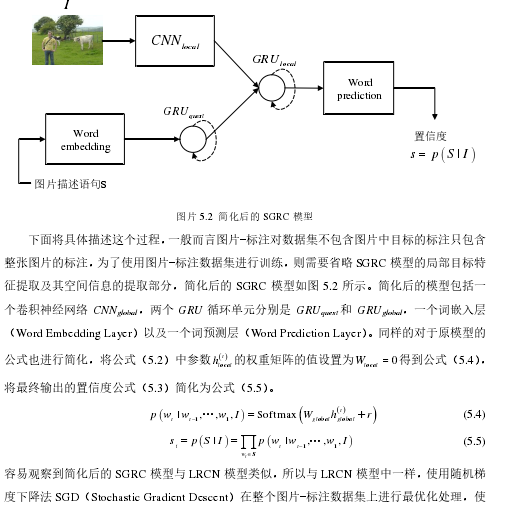


其中,N 是数据集图片的个数,Oi是数据集第i个图片中被标注的目标的个数,i, jT 表示图片中第j个被标注目标的标注个数。
5.4 实验与结果分析
5.4.1 实验设计
本章实验的数据集是Refer It,Refer It数据集是一个大型公开的图片数据集。该数据集包含了来自数据集IAPRTC-12的20000张图片,并且每张图片都对目标在图片中的局部区域进行了标注,整个数据集包含120K个目标局部区域的文本标注。在本节实验中,将该数据集进行了划分,其中10000张图片及其目标区域标注作为训练数据,另外10000张图片及其目标区域标注作为测试数据。构造该数据集训练数据与测试数据的(图片,边界框,文本描述)实例元组,对于训练数据一共有59976个(图片,边界框,文本描述)实例元组,对于测试数据一共有60105个(图片,边界框,文本描述)实例元组。
在本次实验过程中,将本章的模型与两个已有的方法模型的实验结果进行了对比。这两个模型分别是Wu等人提出的基于词袋(Bag of Words)的CAFFE-7K模型和Donahue等人提出的LRCN模型。对于CAFFE-7K模型,将图片的词袋(Bag of Words)表示以及查询语句分别映射成两个向量,通过计算这两个向量的余弦距离获得置信度;对于LRCN模型,在数据集MSCOCO上进行训练。原文中用来完成图片的查询,在本章实验中,将数据集中Refer It图片I中的目标的局部图片区域Ibox和自然搜索语句输入Squery该模型中,输出搜索语句对应目标区域的条件概率( )|quest boxp S I,并且将其作为图片中目标对于搜索语句的置信度分数。
本章提出的SGRC模型先在图片-标注数据集MSCOCO上预训练,使用随机梯度下降法SGD作最优化处理。预训练完成后,使用章节 提出的方法将为获得剩余未被学习到的参数。
接着将数据集Refer It的(图片,边界框,文本描述)实例元组输入到SGRC模型中进行模型的微调,通过反向传播进行训练。
为了测试查询目标的空间信息spatialx 和全局场景特征globalx 对实验结果影响,在数据集Refer It微调网络的过程中,通过调整参数获得不同输入条件下SGRC模型的实验结果。在神经网络微调阶段,将空间信息spatialx 与权重矩阵globalW 设置为0,获得没有空间信息spatialx 以及全局场景特征globalx 作为输入的SGRC模型,记做SGRC(without spatial, global)。同样的,仅仅设置权重矩阵globalW 为0,可获得没有全局场景特征globalx 作为输入的SGRC模型,记做SGRC(without global)。为了测试迁移学习对实验结果的影响,在训练过程中将不再使用迁移学习。忽略在数据集MSCOCO上的预训练,直接在数据集Refer It进行训练。因为没有预训练的过程,无法得到权重矩阵globalW 的初始参数,所以将空间信息spatialx 与全局场景特征globalx 都设置为0,这时的SGRC模型记做SGRC(without spatial, global, transfer)。
5.4.2 结果分析
在测试阶段,将以上提到的4种SGRC模型与基于词袋(Bag of Words)的CAFFE-7K模型以及LRCN模型进行对比,输出局部目标图片区域Ibox是自然语言搜索语句Squery的结果的置信度,计算高置信度区域是正确搜索结果的准确率。具体的结果如表5.1所示。

由表5.1中可观察到,基于词袋(Bag of Words)的CAFFE-7K模型的搜索准确率比较低,因为CAFFE-7K模型的词袋映射是基于数据集Image Net的,Refer It数据集的目标文本标注语句一旦出现数据集Image Net中不包含的标签词时,将无法准确的确定搜索目标。进一步观察得知,本章提出的SGRC模型的目标搜索准确率要比CAFFE-7K模型和LRCN模型高,并且SGRC模型在4个情况下的搜索准确率逐步提升,这说明目标的空间信息spatialx 、全局场景特征globalx 和SGRC模型在其他领域数据集上的迁移学习,都在一定的程度上改善了目标的自然语言搜索。
5.5 本章小结
本章对于基于深度学习的自然语言目标搜索技术进行深入的研究和探索,提出了一种基于GRU模型的视频目标自然语言搜索算法,分别从目标的局部图片区域、目标区域的空间信息、整个图片的全局场景信息和自然语言搜索语句这四个方面提取特征;再通过两层的GRU神经网络,融合这四个方面的特征完成自然语言目标搜索。另外,详述了本章提出的基于GRU模型的迁移学习过程,通过在图片-标注数据集上预先训练获得初始的参数,然后在目标自然语言搜索数据集上通过反向传播进行微调网络。在测试阶段以高置信度目标候选区域的搜索准确率作为评价标准。实验结果表明,本章提出的自然语言搜索模型SGRC能够有效进行视频中目标的搜索,并且该模型的搜索准确率要比现有的两种目标搜索模型CAFFE-7K、LRCN要高,说明该模型能够更加准确的进行视频目标的搜索。
但是该模型仍然存在很多不足的地方需要进行改进与提高,本章中只是考虑了存在固有形状目标的检测,比如“人物”,“小狗”等等,那些不存在固定形状的目标无法被准确的搜索到,比如“天空”,“马路”等等[55,56].如果能够解决好无固定形状目标的搜索,视频中自然语言目标搜索的能力必定会获得更大的改善。