







本篇文章目录导航:
【题目】研究深度学习的目标检测与搜索算法??
【第一章】基于深度学习的视频运动目标绪论
【第二章】学习视频运动目标相关工作
【第三章】基于卷积神经网络的视频目标定位检测
【第四章】基于时空双流的视频人物动作检测
【第五章】基于循环神经网络的视频目标自然语言搜索
【第六章】目标检测与搜索算法的结论与参考文献
第四章 基于时空双流的视频人物动作检测
第三章中已经概述了基于深度卷积的高定位精确性目标检测。在第一章说明,视频运动目标的检索可以从视频中运动目标检测、视频中人物的动作检测以及视频的查询搜索三方面入手,在本章中为了研究视频中人物动作的检测,首先进行了视频空间与时间特征的提取,并且取得了不错的动作识别效果。为此本章提出了一种基于3D卷积神经网络的时空双流人物动作识别模型。
4.1 问题描述
在传统的视频人物动作识别方法中,Simonyan等人提出一种时空双流的深度学习策略[46],用来分别提取视频的空间信息与时间信息。首先提取视频的RGB帧和连续视频光流帧,将视频分解成空间与时间元素。然后将这两个元素分别输入到两个独立的深度卷积神经网络当中,来学习场景中运动目标外形以及动作的空间以及时间信息。这两个流分别进行视频行为动作的识别,在最后将softmax层的分数通过晚期融合(late fusion)的方式进行合并[47].
相比传统的视频人物动作识别方法,该方法有效的融合了视频的时间信息,提高了动作识别准确性,但仍然存在如下问题:
Simonyan提出的深度学习结构的输入量太少,仅仅是单个光流帧以及若干个时间域上等间隔抽样的光流;Simonyan提出的空间特征与时间特征的融合仅仅是在最后的softmax层进行融合,没有考虑到空间与时间特征之间的关联性以及这些关联如何随着时间变化。
基于上述方面的考虑,本章对于Simonyan提出的时空双流深度学习模型的改进基础上,引入了3D卷积神经网络,提出一种基于视频深度学习的时空双流视频人物动作识别模型(Spatio-Temporal Convolutional Neural Network based on 3D-Gradients,Spatiotemporal-3DCNN)。
4.2 基于时空双流的融合特征
提取进行视频中人物的动作识别的,首先要做的是提取视频中人物动作的特征。本章节的重点解决如何充分的提取视频帧随着时间变化的特征,并且将该时间特征与视频帧的空间特征进行有效的融合。本章主要从三个方面来研究:空间流卷积神经网络、时间流卷积神经网络、时空融合策略。
4.2.1 空间流卷积神经网络空间
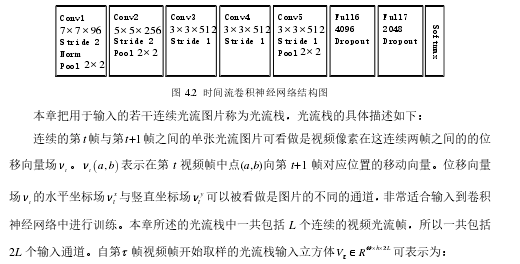
流卷积神经网络的输入是单个视频帧,是一种通过提取静态图片信息来完成视频人物动作识别的深度学习模型。静态的外形特征是一个非常有用的信息,因为视频人物的某些行为动作与某些物体有着密切的关联性。通过后面章节的实验也可得知,仅仅通过空间流卷积神经网络也能够完成部分视频人物动作的识别。空间流卷积神经网络在本质上属于一种图片分类结构,本章所述的空间流卷积神经网络结构使用的是Krizhevsky A等人提出的图片分类卷积神经网络[48],其具体结构采用的是牛津大学视觉几何组(Visual Geometry Group,VGG)开发的VGG-M-2048模型如图4.1所示。并且该结构会在图片数据集进行预训练。

4.2.2 时间流卷积神经网络时间
流神经网络结构如图4.2所示,同样也是采用的是VGG-M-2048模型,与空间流卷积神经网络不同时间流卷积神经网络输入的是若干连续视频帧之间的光流图片。光流图片可以理解为连续视频帧之间的像素点位移场,显示的表述了视频的运动信息,有效的提取了视频的时间特征,提高了视频人物动作识别的准确率。
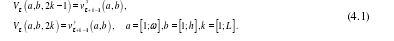
公式(4.1)中,w和h分别表示视频的像素长度与像素宽度。
4.2.3 时空特征融合策略
时空网络的融合在与使用视频的空间特征与时间特征的关联性判断人物的行为动作。比如对于梳头与刷牙两个行为动作,空间流网络识别出了静态的物体头发与牙齿,时间流网络识别出了在一定的空间位置手部进行周期性的运动,结合这两个网络可以分辨梳头和刷牙这两个人物动作。本章节从时空双流的融合位置角度进行阐述时空双流卷积神经网络融合策略。
神经网络之间的融合不是简单地将一个神经网络叠加到另一个神经网络,首先要考虑的是特征图的大小是否一致,如果不一致需要对较小的特征图进行上采样。接着还要考虑空间流卷积神经网络与时间流卷积神经网络通道之间的对应关系。本章所述的结构使用的时空融合方法具体可用如下公式进行描述:


4.3 基于3D卷积神经网络的人物动作检测
本章4.2节分析了时空特征的提取方法以及融合时空特征的方法,这一节将主要利用上一节提取的时空特征输入3D卷积神经网络[49],最终识别出视频人物的动作。
4.3.1 整体框架设计
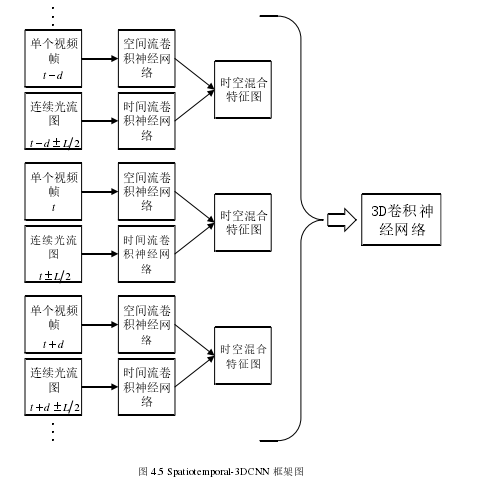
本章提出的Spatiotemporal-3DCNN框架图如图4.5所示。该模型主要包括三个模块:空间特征与时间特征的提取、空间特征与时间特征的融合、基于3D卷积神经网络的视频人物动作识别。首先,分别训练两个2D卷积神经网络流,用来分别提取视频的空间特征与时间特征;之后,将空间流与时间流网络进行再卷积层进行融合,并对参数进行微调,用于提取视频时空中层特征。最后,通过3D卷积神经网络模型完成视频人物动作的识别。
Spatiotemporal-3DCNN包含T个时空流。空间流的输入的是视频帧,从视频片段的时间t开始以时间域距离d进行等间隔取样,将在时间t,t+d,…,t+Td 的视频帧作为输入。时间流对应的输入是连续光流帧,在时间t时刻对应的连续光流帧图片在时间域上的位置是(t-L/2,t+L/2)。通过融合得到在时间域上连续的T个时空特征图,并且光流域的长度L和空间流视频帧的取样间隔d必定满足关系L<d.
Spatiotemporal-3DCNN利用3D卷积神经网络对2D时空双流卷积神经网络在时间轴上的进一步扩展,充分利用了视频的时间信息。这里时空双流卷积神经没有使用全连接层最后的特征融合,因为全连接层输出的是高层特征会丢失图像特征在时间轴上的信息。将时空双流在卷积层(conv5)的时空特征进行融合得到的特征图作为3D卷积神经网络的输入,提高了时空特征在像素点上的关联性,因为在模型输入中加入了光流图片,提高了处理静态图像视频帧采样的鲁棒性,每一秒的采样都会都是帧图像的所隐含的运动信息,而光流特征可以作为补偿。接着3D卷积神经网络进而对同一人物动作视频的不同时间片段的时空特征图进行3D卷积与池化进一步提取了时间信息。
4.3.2 3D 卷积神经网络动作检测
本章本节提出的3D卷积神经网络模型如图4.6所示,这种网络结构包含5个卷积层、5个池化层、2个全连接层以及一个识别视频行为动作的softmax损失层。这5个卷积层所使用的卷积核的数量依次是64,128,256,256,256.与传统的卷积神经网络不同的是,3D卷积神经网络不仅仅对空间的水平与竖直维度进行卷积,同时将时间维度也考虑在内进行3D卷积,所有的3D卷积核的大小都是3×3×3,在空间与时间维度上的深度都是3,并且在时间与空间维度的跨度是1×1×1.池化层采用的池化方法是max pool,3D池化核的大小都是2×2×2,在空间与时间维度上的深度都是2,在时间与空间维度上的跨度是1×1×1.
3D卷积神经网络的第一层输入是由时空双流结构提取的T个中层时空特征图M RH W D T? ? ??
,其中H是时空特征图的高度,W是时空特征图的宽度,D是时空特征图的通道数。最后的两个全连接层都是2048维的特征向量。

4.4 实验与结果分析
4.4.1 实验设计
本章实验的数据集来源于两个有名的视频动作识别数据集:UCF-101与HMDB51.UCF-101是目前动作类别数、样本数最多的数据库之一,一共包含13320段视频样本101个视频类别,其数据库样本来自从BBC/ESPN的广播电视频道收集的各类运动样本、以及从互联网尤其是视频网站You Tube上下载而来的样本。
HMDB51数据集包含6849段视频样本51个视频类别,视频多数来自于电影,小部分来自于公共数据库以及You Tube等网络视频库。
本章将这两个数据集都分成3份训练集与测试集进行实验,通过计算同一数据集3份实验的准确率的平均值作为最终的实验结果。
本章提出的Spatiotemporal-3DCNN模型的主要实验过程,主要分为三大步:
(1)预训练空间与时间流卷积神经网络本节中使用两个预先训练的图片分类模型来单独训练空间流卷积神经神经网络和时间流卷积神经网络。
VGG-M-2048模型具有5个卷积层和3个全连接层,结构更深层的牛津大学视觉几何组(Visual Geometry Group,VGG)开发的VGG-16模型具有13个卷积层和3个全连接层。在训练空间流卷积神经网络的过程中,使用单个视频帧图像对预先在图片数据库Image Net上训练的模型进行训练,输入的是大小为224×224视频帧随机位置裁剪的子图,并且对这个子图进行水平翻转和RGB随机颜色抖动增加训练的数据。时间流卷积神经网络的训练过程中,同样也使用了图像分类模型进行训练,输入立方体是大小为224×224×2L 在原光流图像上随机位置裁剪的连续子视频光流帧。根据Simonyan等人提出的结论,将光流在时间域上的长度设置为L=10 表现效果最好。将丢失率设置为0.85,初始的学习率设置为10-2,在第30K次迭代后每20K次迭代将学习率缩小为原先的十分之一,迭代80K次后停止训练。
(2)训练时空混合卷积神经网络本节在上述空间流与时间流卷积神经网络的基础上进行时空双流融合网络的训练。实验过程中将会尝试在不同的卷积层进行融合,并且通过上采样的方法是两个神经网络的特征图分辨率大小一致。没有在全连接层进行融合,因为全连接层在某些程度上已经破坏了时间与空间特征,不能有效的提高识别准确率。在训练的过程中,每一批的大小设置为96,通过反向传播对融合后的结构参数进行微调。初始的学习率设置为10-3,在迭代14K次后学习率降为10-4,在迭代30K次后停止训练。训练完成后的时空融合结构可被用于初步的提取时空融合特征。
(3)基于3D卷积神经网络的人物动作识别本节将由时空混合卷积神经网络提取到的中层时空特征输入到3D卷积神经网络当中进行训练,这个过程中进一步提取利用的时间特征并且完成了人物动作的识别。将连续等间隔时间段的时空特征图作为3D卷积神经网络的输入,抽样的起始时间随机选取,时间段个数取值为T=5,并且每个融合的时空特征图共有1024个特征通道。
3D卷积核的大小为3×3×3并且在第一个卷积层共有64个卷积核。
3D卷积神经网络比较容易过拟合,所以丢失设置较高为0.9.初始的学习率设置为0.003,每150K次迭代会将学习率除以2,当迭代次数达到1.9M是停止训练。
4.4.2 结果分析
实验过程中采用了两种数据库UCF-101和HMDB-51,并将它们分成3份,每份UCF-101数据集包含9.5K个训练视频,每份HMDB-51包含3.7K个训练视频。对数据集分成的3份内容都进行训练与测试,得到3个视频人物动作识别准确率。本节中将得到的3个识别准确率的加权平均值作为视频人物动作识别模型的定量评估。
空双流结构的动作识别准确率如表4.1所示。由表4.1可知双流在卷积层进行融合时,从conv1层到conv5层动作识别的准确率逐步提升,说明在卷积层中更深层的融合能够更加有效的利用时空信息。同时表4.1给出了Simonyan等人提出的时空双流卷积神经网络的识别准确率,该结构在softmax层进行融合,结果表明在卷积层(conv5)融合结构略优于在softmax层融合的结构。本章提出的时空域3D卷积神经网络模型,都将在最深层次的卷积层进行融合提取中层时空特征图。本章最终的模型使用更深层的神经网络模型VGG-16模型来提取中层融合时空信息,之后将提取到的中层时空信息输入到3D卷积神经网络中。本节中会将提出的时空域3D卷积神经网络模型与Donahue等人提出的长周期循环卷积神经网络模型(Long-term Recurrent Convolutional Networks,LRCN)、Du Tran等人[50]
提出的3D卷积神经网络模型(Convolutional Neural Network based on 3D-Gradients,C3D)、Simonyan等人提出的双流卷积神经网络模型(Two-Stream Convolutional Neural Network,Two-Stream Convnet)和Lin Sun等人[51]
提出的因式分解卷积神经网络模型(Factorized Convolutional Neural Network,Factorized Conv Net)进行了对比。从表格4.2可以看出单个的时间流与空间流卷积神经网络也能够识别部分视频人物动作,并且可以看出本章提出的时空双流3D卷积神经网络模型能够更加精确的识别出视频人物动作。
空双流结构的动作识别准确率如表4.1所示。由表4.1可知双流在卷积层进行融合时,从conv1层到conv5层动作识别的准确率逐步提升,说明在卷积层中更深层的融合能够更加有效的利用时空信息。同时表4.1给出了Simonyan等人提出的时空双流卷积神经网络的识别准确率,该结构在softmax层进行融合,结果表明在卷积层(conv5)融合结构略优于在softmax层融合的结构。本章提出的时空域3D卷积神经网络模型,都将在最深层次的卷积层进行融合提取中层时空特征图。本章最终的模型使用更深层的神经网络模型VGG-16模型来提取中层融合时空信息,之后将提取到的中层时空信息输入到3D卷积神经网络中。本节中会将提出的时空域3D卷积神经网络模型与Donahue等人提出的长周期循环卷积神经网络模型(Long-term Recurrent Convolutional Networks,LRCN)、Du Tran等人[50]
提出的3D卷积神经网络模型(Convolutional Neural Network based on 3D-Gradients,C3D)、Simonyan等人提出的双流卷积神经网络模型(Two-Stream Convolutional Neural Network,Two-Stream Convnet)和Lin Sun等人[51]
提出的因式分解卷积神经网络模型(Factorized Convolutional Neural Network,Factorized Conv Net)进行了对比。从表格4.2可以看出单个的时间流与空间流卷积神经网络也能够识别部分视频人物动作,并且可以看出本章提出的时空双流3D卷积神经网络模型能够更加精确的识别出视频人物动作。
空双流结构的动作识别准确率如表4.1所示。由表4.1可知双流在卷积层进行融合时,从conv1层到conv5层动作识别的准确率逐步提升,说明在卷积层中更深层的融合能够更加有效的利用时空信息。同时表4.1给出了Simonyan等人提出的时空双流卷积神经网络的识别准确率,该结构在softmax层进行融合,结果表明在卷积层(conv5)融合结构略优于在softmax层融合的结构。本章提出的时空域3D卷积神经网络模型,都将在最深层次的卷积层进行融合提取中层时空特征图。本章最终的模型使用更深层的神经网络模型VGG-16模型来提取中层融合时空信息,之后将提取到的中层时空信息输入到3D卷积神经网络中。本节中会将提出的时空域3D卷积神经网络模型与Donahue等人提出的长周期循环卷积神经网络模型(Long-term Recurrent Convolutional Networks,LRCN)、Du Tran等人[50]
提出的3D卷积神经网络模型(Convolutional Neural Network based on 3D-Gradients,C3D)、Simonyan等人提出的双流卷积神经网络模型(Two-Stream Convolutional Neural Network,Two-Stream Convnet)和Lin Sun等人[51]
提出的因式分解卷积神经网络模型(Factorized Convolutional Neural Network,Factorized Conv Net)进行了对比。从表格4.2可以看出单个的时间流与空间流卷积神经网络也能够识别部分视频人物动作,并且可以看出本章提出的时空双流3D卷积神经网络模型能够更加精确的识别出视频人物动作。

图4.7为数据集部分视频中人物动作识别正确案例的展示。视频(a)(b)(c)表示了刷牙,剃胡子与头部按摩三种相似的人物动作,视频(d)(e)(f)表示了三种常见的体育运动。

4.5 本章小结
本章提出了一种基于视频深度学习的时空双流人物动作识别模型,来完成视频中的人物动作识别任务。该模型先利用预先训练好的图片分类模型训练空间流与时间流卷积神经网络,并在最深层次的卷积层进行时空双流的融合,完成中层时空特征信息的提取;再将提取的中层时空特征信息输入到3D卷积神经网络中,来完成识别视频人物动作识别任务。实验表明本节提出的动作学习模型能够比较有效地识别出部分视频中人物简单的动作。
但是,本章仍存在很多不足之处需要改进与提高,比如视频中的音频、文本等固有信息没有充分地利用与考虑,以及当视频出现多人物并且存在互相遮挡,这些都是识别视频中人物语义的重要线索[52,53].如果可以很好的利用与融合这些线索信息,视频中人物动作能力必定会得到很大的提升,后面章节本人将会继续研究怎么利用自然语言查询视频内容。